Java SpringBoot與Vue.js構建的高校實習管理系統 設計與實現
在當今高等教育中,實習是連接理論學習與社會實踐的關鍵橋梁。針對高校實習管理中普遍存在的流程繁瑣、信息分散、溝通不暢等問題,設計與實現一個高效、便捷、一體化的實習管理系統顯得尤為重要。本文將詳細探討一個基于Java SpringBoot后端框架與Vue.js前端框架的計算機畢業設計項目——“高校實習管理系統”,旨在為計算機及相關專業的學生提供一個完整的設計與實現思路。
一、 系統概述與目標
系統定位:本系統是一個面向高校、實習企業、學生及指導教師四方的B/S架構Web應用。其核心目標是利用信息化手段,對實習全過程(包括崗位發布、申請、過程管理、報告提交、成績評定等)進行規范化、數字化管理,提升各方協作效率與實習質量。
核心目標:
1. 流程標準化:將分散的實習流程整合到統一平臺,實現無紙化、可追溯的管理。
2. 信息透明化:為學生提供豐富的實習崗位信息,為企業提供可靠的學生簡歷庫,消除信息壁壘。
3. 管理高效化:為學院管理者和指導教師提供便捷的批量處理、進度監控與數據統計工具。
4. 溝通便捷化:集成站內信、通知公告等功能,確保實習期間信息傳遞及時、準確。
二、 系統架構設計與技術選型
本系統采用目前主流的“前后端分離”架構,后端負責業務邏輯與數據持久化,前端負責用戶交互與數據展示,二者通過RESTful API進行通信。
1. 后端技術棧 (Server-side)
核心框架:Spring Boot。其“約定優于配置”的理念極大地簡化了Spring應用的初始搭建和開發過程,內置Tomcat服務器,便于快速部署。
數據持久層:MyBatis-Plus。作為MyBatis的增強工具,提供了強大的CRUD操作和條件構造器,減少了大量SQL編寫工作,提升了開發效率。
數據庫:MySQL。成熟穩定的開源關系型數據庫,滿足系統對事務性和結構化數據存儲的需求。
安全與權限:Spring Security + JWT (JSON Web Token)。用于實現用戶認證與細粒度的權限控制(如學生、企業HR、指導教師、管理員等不同角色)。
* 其他工具:Lombok(簡化代碼),Swagger2 / Knife4j(API文檔生成與調試),Redis(可選,用于緩存熱點數據或會話管理)。
2. 前端技術棧 (Client-side)
核心框架:Vue.js。漸進式JavaScript框架,輕量、易學,組件化開發模式非常適合構建復雜的單頁面應用(SPA)。
UI框架:Element-UI 或 Ant Design Vue。提供豐富的、美觀的UI組件,能快速搭建出風格統一的界面。
狀態管理:Vuex。用于集中管理所有組件的狀態,解決多組件共享狀態的問題。
路由管理:Vue Router。實現前端路由,構建單頁面應用。
* 網絡請求:Axios。基于Promise的HTTP客戶端,用于向后端發起RESTful API請求。
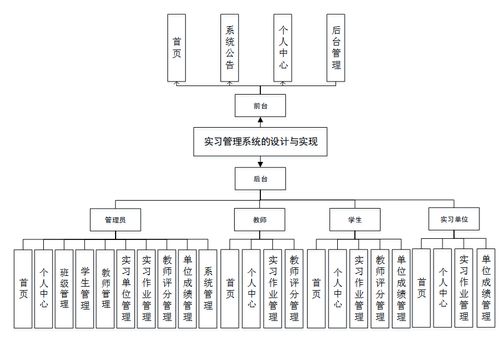
三、 核心功能模塊設計
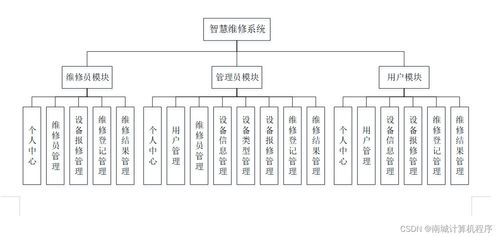
系統主要分為四大角色門戶,功能模塊相互關聯。
1. 學生端
個人信息管理:維護個人簡歷、聯系方式等。
實習崗位瀏覽與搜索:按企業、地點、崗位類型等條件篩選心儀崗位。
在線申請與投遞:一鍵投遞簡歷,查看申請狀態(待處理、已通過、已拒絕)。
實習過程管理:提交周報/月報、實習日志,在線提交實習報告。
* 消息中心:接收企業、導師的通知與反饋。
2. 企業端
企業信息認證與管理:提交營業執照等資料,由管理員審核通過。
崗位發布與管理:發布、編輯、下架實習崗位,設定要求與名額。
簡歷篩選與處理:查看投遞學生的簡歷,進行“通過/拒絕”操作,發送面試通知。
實習評價:實習結束后,在線為學生填寫實習表現鑒定。
3. 指導教師端
學生分組管理:查看名下指導的學生列表及其實習狀態。
過程監督與指導:審閱學生提交的周報、報告,在線批注與評分。
成績評定:綜合企業評價、報告質量等,給出最終實習成績。
溝通與通知:向指導的學生群發通知或單獨聯系。
4. 系統管理端 (管理員)
用戶管理:審核企業注冊信息,管理所有用戶賬戶(啟用/禁用)。
全局監控:查看全院的實習數據統計(如崗位數量、申請分布、實習完成率等)。
公告管理:發布面向全院或特定群體的系統公告。
系統設置:維護基礎數據字典(如專業列表、實習類型等)。
四、 關鍵技術與實現難點
- 權限控制的實現:利用Spring Security的過濾器鏈和基于角色的訪問控制(RBAC)模型,在接口層面(
@PreAuthorize("hasRole('STUDENT')"))和前端路由層面進行雙重校驗,確保不同角色只能訪問授權范圍內的資源。
- 文件上傳與管理:實習報告、企業認證材料等文件的上傳是核心功能。可采用將文件存儲在服務器特定目錄(或云存儲OSS),并在數據庫中記錄文件路徑的方式。需注意文件大小限制、格式校驗和訪問權限控制。
- 實時消息推送:為了提升用戶體驗,可引入WebSocket技術(如SockJS + Stomp)實現簡單的實時通知,例如當學生的申請被處理時,能即時收到前端提示。對于輕度需求,也可通過前端定時輪詢API實現。
- 數據統計與可視化:后臺管理需要直觀的數據展示。后端提供聚合數據的API,前端可借助ECharts等圖表庫,將實習數據、學生分布等以柱狀圖、餅圖等形式呈現。
五、 與展望
本項目通過整合Java SpringBoot與Vue.js的技術優勢,設計并實現了一個功能完備、架構清晰的高校實習管理系統。它不僅為計算機專業畢業生提供了一個涵蓋需求分析、系統設計、編碼實現、測試部署全流程的綜合性實踐課題,更具備實際應用價值,能夠切實改善高校實習管理的現狀。
未來展望:系統可進一步擴展人工智能崗位推薦、實習過程視頻打卡簽到、與企業HR系統對接等功能,并向移動端(微信小程序)延伸,打造更加智能化、移動化的實習服務生態。
如若轉載,請注明出處:http://m.hwgood.cn/product/47.html
更新時間:2026-06-19 03:07:50